Project Overview


Project Type:
Role
Project Outcome
Methods
Deliverables
Tools
Project on Loan Default Prediction
Data Scientist / Machine Learning Engineer
1. Developed a classification model to predict which clients will likely default on their loans, helping the bank make informed decisions.
2. Implemented multiple machine learning algorithms, including Random Forest, XGBoost, SVM, and Logistic Regression, to compare their effectiveness in terms of recall and precision.
3. The final model delivered reliable predictions with a focus on maximizing recall to minimize the risk of approving loans to potential defaulters.
1. Conducted extensive Exploratory Data Analysis (EDA) to understand relationships between key features and loan default risk.
2. Employed data preprocessing techniques such as feature encoding, standardization, and handling of missing data.
3. Applied k-fold cross-validation to optimize model performance and ensure generalization.
1. A loan default prediction model with strong performance, providing valuable business insights into which clients are at high risk of default.
Python, Pandas, Scikit-learn, XGBoost,AdaBoost, Decision Tree Classifier, Random Forest, Matplotlib, Seaborn, Google Colab.
Context
Loan Default Prediction:
Bank loan defaults are a significant concern, especially for home equity loans. Banks need a reliable way to predict which customers are most likely to default, helping them minimize Non-Performing Assets (NPAs).
This project seeks to build an accurate and interpretable loan default prediction model. This will enable the bank to justify decisions about loan approvals and rejections in compliance with the Equal Credit Opportunity Act (ECOA).
Objective
-
Develop a robust classification model to accurately predict which clients are likely to default on their loans.
-
Identify the most important features affecting loan defaults to improve the bank's decision-making processes.
Key Research Questions
-
What are the main factors that influence loan defaults?
-
Do applicants who default have a significantly different loan amount compared to those who repay their loan?
-
Which machine learning models perform best for predicting loan defaults?
-
What are the trade-offs between precision and recall when predicting loan defaults?
PHASES OF PROJECT
This Loan Default Prediction System project progressed through six phases: Data Discovery, Data Preparation, Model Planning, Model Building, Communicating Results, and Operationalizing the system for real-world use. Each phase was crucial in developing and optimizing the recommendation model.

Data Discovery
Goal:
Identify and gather relevant data to build the music recommendation system.

Data Preparation
Goal:
Clean and prepare the data for further analysis.

Model Planning
Goal:
Decide on the most appropriate algorithm to build the recommendation system.

Model Building
Goal:
Develop and train the recommendation model.

Communicating Results
Goal:
Present the model’s performance and insights to stakeholders.

Operationalize
Goal:
Deploy the model in a real-world environment and monitor its performance.

Data Discovery

Phase-1
1 / Datasets:
-
The dataset, Home Equity Dataset (HMEQ), consisted of 12 features, including loan amount, mortgage due, job type, and debt-to-income ratio. The target variable was BAD, indicating whether the applicant defaulted on the loan (1) or repaid it (0).
2 / Initial Data exploration
-
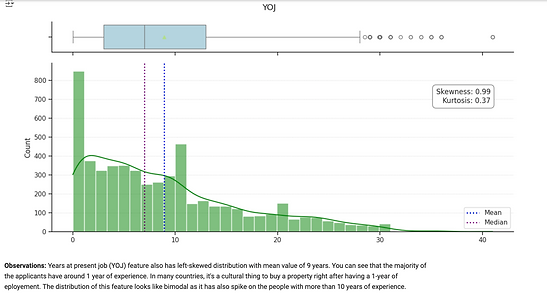
Initial analysis focused on identifying potential correlations between the features and default risk, and understanding the distributions of key variables such as loan amount and years on the job (YOJ).
Key Insights
-
Preliminary analysis indicated that features such as loan amount, debt-to-income ratio, and mortgage due had significant correlations with default risk.
-
The Years on Job (YOJ) feature was left-skewed, with a large proportion of applicants having only 1 year of job experience, which was informative for predicting stability.
Challenges
-
Managing missing values, particularly for the YOJ and DEROG features, required careful imputation to avoid bias.
Data Preparation


Phase-2
1 / Missing Value Imputation:
-
Missing values were imputed using the mean for continuous variables (e.g., loan amount, YOJ) and the mode for categorical variables (e.g., REASON, JOB).
2 / Feature Engineering and Encoding
-
One-hot encoding was applied to categorical features like REASON and JOB to convert them into a suitable format for machine learning models.
3 / Outlier Detection:
The Outliers in numeric features such as loan amount and mortgage due were detected and either removed or transformed to reduce their impact on the model’s performance.
4 / Standardization:
Continuous variables, particularly loan amount and debt-to-income ratio, were standardized to improve the performance of models sensitive to feature scaling, such as SVM and Logistic Regression.
Key Insights
-
Imputation of missing data ensured that all observations were retained for analysis, improving model training.
-
Standardizing the continuous variables was necessary for algorithms like Logistic Regression to perform optimally.
Challenges
-
Maintaining data integrity while imputing missing values and handling outliers without distorting the underlying distributions was crucial.
Phase-3
1 / Process:
-
A variety of classification models were selected to capture both linear and non-linear relationships:
-
Linear Models:
-
Logistic Regression: Chosen for its interpretability and simplicity. Before implementation, collinearity among variables was checked using the Variance Inflation Factor (VIF) to ensure that multicollinearity did not bias the model.
-
-
Non-linear Models:
-
Decision Tree Classifier: Selected for its ability to model non-linear relationships between features and default risk.
-
Support Vector Classifier (SVC): Used to separate defaulters and non-defaulters by finding the optimal hyperplane in a high-dimensional space.
-
K-Nearest Neighbors (KNN): Implemented to classify new applicants based on the proximity of their features to known defaulters.
-
Gaussian Naive Bayes (GaussianNB): Applied to handle classification using a probabilistic approach, assuming feature independence.
-
-
Ensemble Models:
-
Random Forest: Built using an ensemble of decision trees, designed to reduce variance and increase prediction accuracy.
-
AdaBoost: Boosting technique used to improve weak learners by focusing on misclassified instances.
-
Gradient Boosting (XGBoost): Implemented to enhance model performance by optimizing errors using gradient descent techniques.
-

Model Planning
Challenges
-
Selecting the appropriate model to balance recall and precision was critical to ensuring that the bank did not reject too many legitimate applicants while minimizing the risk of defaults.

Model Building

Ensemble Method: Random Forest Classifier Learning Curve

Base Model, Ensemble Method:Ada Boost classifier Learning Curve

Hypermeter tuning Confusion Matrix
Ensemble Method: Random Forest Classifier Learning Curve
Learning curves of all the models.
5 / Hyperparameter Tuning:
Applied primarily to Decision Tree and XGBoost models using GridSearchCV to find the optimal values for parameters such as max depth, learning rate, and number of estimators.
Phase-4
1 / Ensemble Methods:
Random Forest, AdaBoost, XGBoost were implemented to aggregate the predictions of multiple weak learners, improving the overall performance of the model.
2 / Non-Linear Methods:
SVC, KNN, GaussianNB tested to explore non-linear relationships between the features and loan default risk.
3 / Decision Tree Classifier:
Optimized through GridSearchCV for parameters such as tree depth, minimum samples per split, and split criteria to prevent overfitting and improve performance.
4 / Logistic Regression:
Checked for multicollinearity using Variance Inflation Factor (VIF) before fitting the model to ensure the reliability of its coefficients.
Key Insights
-
XGBoost consistently outperformed other models, achieving the highest recall, which was crucial for identifying high-risk loan applicants.
-
Random Forest provided strong accuracy but slightly lower recall compared to XGBoost
Challenges
-
The hyperparameter tuning process was resource-intensive but essential for improving the performance of decision trees and other models.
Phase-5
1 / Process:
-
Results were communicated using key metrics such as recall, precision, and F1-score, emphasizing the trade-offs between identifying true defaulters and avoiding false positives.
-
Feature importance was presented to the stakeholders, highlighting the most influential features such as loan amount, mortgage due, and derogatory reports.
Communicating Results
Key Insights
-
XGBoost was identified as the best-performing model based on its ability to maximize recall while maintaining acceptable precision.
-
Features like loan amount, mortgage due, and derogatory reports were critical for accurately predicting loan defaults.
Challenges
-
Ensuring that stakeholders understood the implications of the model's predictions, particularly the trade-off between precision and recall, was essential for its successful integration into the loan approval process.
Phase-6
1 / Process:
-
Model retraining and updates were planned periodically to ensure that the predictions remained accurate as new data became available.
Operationalization
Key Insights
-
It is indeed possible to automate the pocess of identifying infected cells in a relatively short time. It doesn't take too long to run on my machine.
Challenges
-
The primary challenge was ensuring that the model could be adapted for future deployment, including addressing potential concerns around regulatory compliance, fairness, and bias in loan decision-making systems.
Reflection
This project was a fantastic hands-on dive into predicting loan defaults. I learned the magic of prepping data—cleaning up missing values and standardizing features made everything run smoother. Testing models like Logistic Regression and XGBoost really highlighted how different algorithms see patterns, with XGBoost being the star of the show. The balancing act between recall and precision taught me a lot about making smart, risk-sensitive decisions. Overall, it was a fun challenge that boosted my skills and got me thinking about how these models could work in the real world.